2023年夏のinter-noiseの発表から戻り、少しづつ気になり始めたのが、
ドイツの哲学者ヘーゲルの言葉「アウフヘーベン」つまり、新しいものが現れた時に古いものと対立しても、その古いものの本質的な部分と融合し、新しい次元に入るという。
ヘーゲルの新しいものが生まれ古いものを駆逐していった場合の世界の変化を肯定するならAIによる音質評価を提唱した場合、古いものの本質と融合する、つまり心理音響パラメーターの本質的なものと融合した音質評価の分析手法が生まれ新しい段階へと移行する。
シン・オンシツヒョウカ・アウフヘーベンが起きるのではないか?
そこで、考えました。心理音響パラメーターの本質的なもので普遍なものってなんだ?
心理音響学の歴史を紐解くならば、スティーブンスのべき乗法、フレッチャーの臨界帯域幅、ツビッカーの臨界帯域をBarkスケールにラウドネス、そしてムーアのERBによるラウドネス。
このような綿々と続いた歴史が、AIが現れて全て消えない。消えるはずがないと。その本質的なものは、当然マスキング効果という人間が持つ現象の解明とモデル化ではないか。画像認識AIと融合したら、こんな構造になるのではないかと。
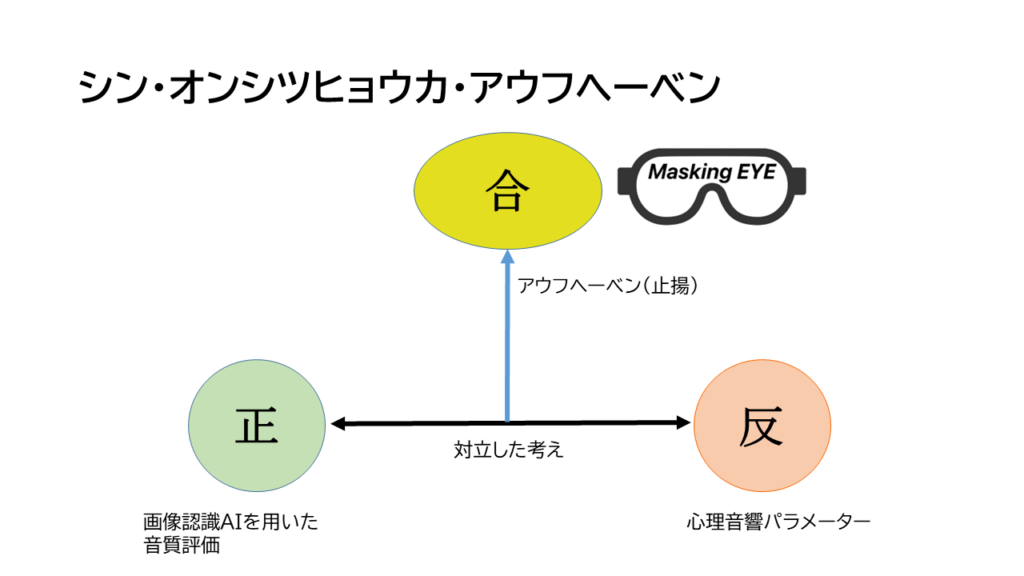
そして、色々考えましたが、画像認識AIとマスキング効果の接点は、こんな例になるのではないでしょうか?
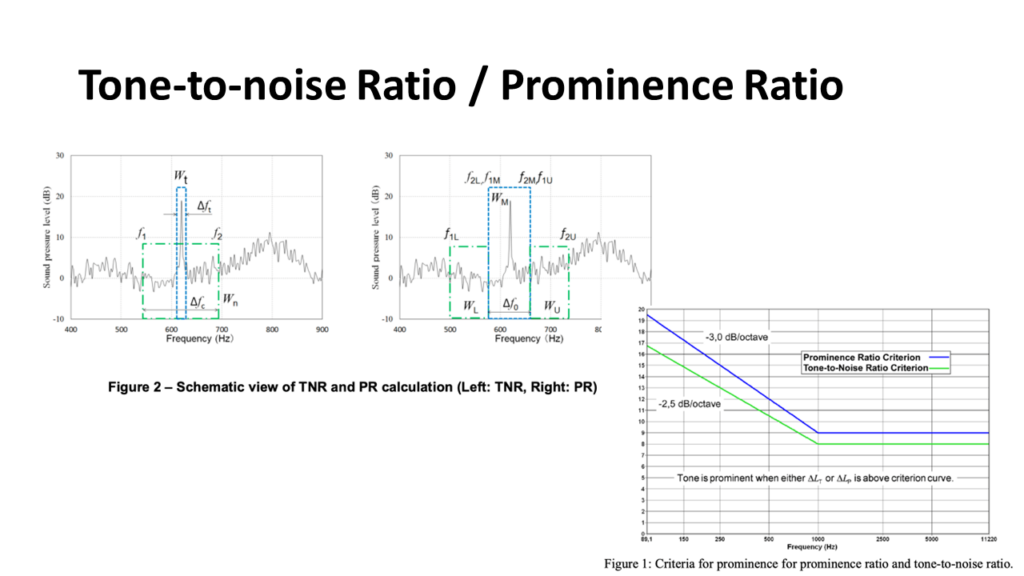
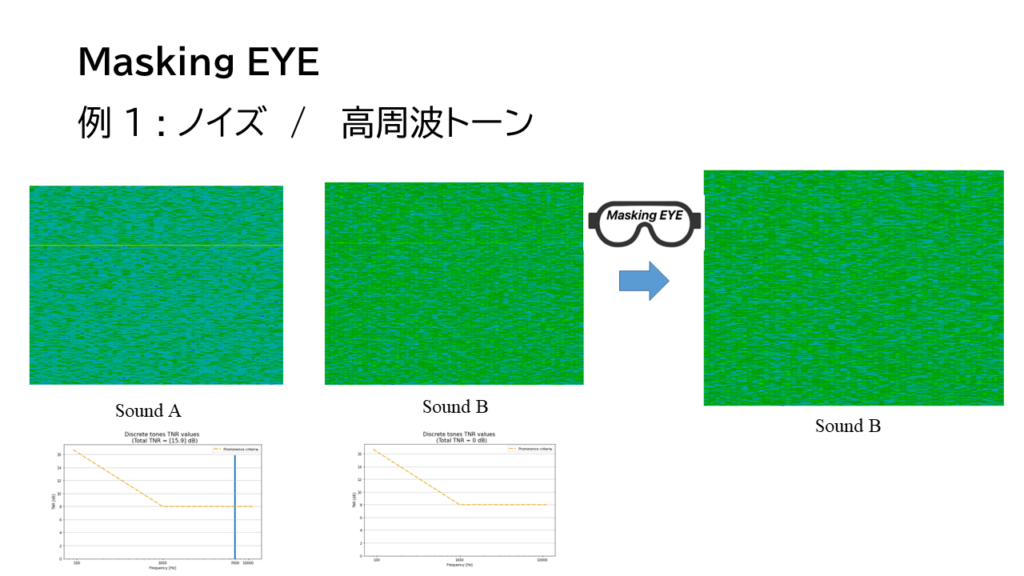
Tone-to-noise RatioやProminence Ratioを持ちいるような事例。ある周波数成分を持つトーンがそのトーンがある臨界帯域幅、またはその近傍の臨界帯域幅の中にあるノイズ成分によりマスキングされる。
右下の図の線より下はマスキングされてトーン音が聞こえない。それより上だと聞こえる。
それを、sFFTによる周波数分析画面で、行うと、こんな問題が直面します。
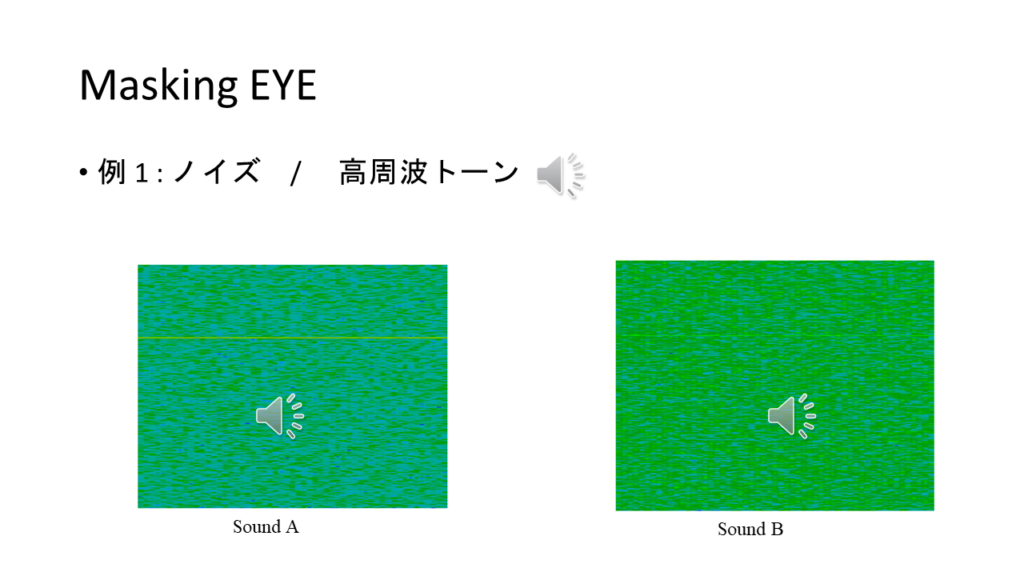
SoundAはsFFT上も音も聞こえますが、SoundBはs FFT上にトーンの成分の線が現れていますが、聴感上聞こえません。(動画参照)
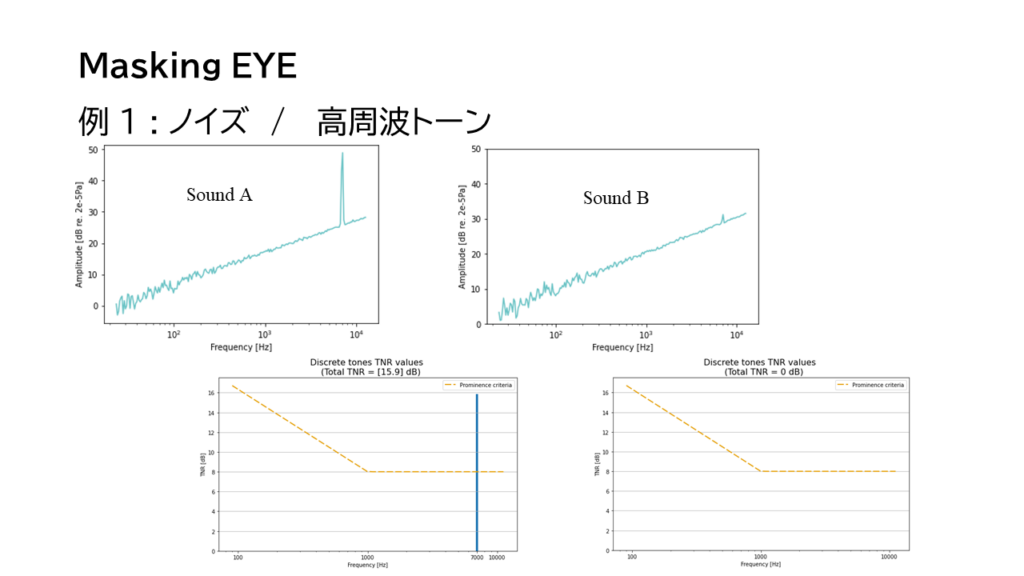
Tone-to-noise RatioでもSoundAは値が現れますが、Bは閾値より下になり聞こえることがないと判定されます。では画像認識AIでSoundBは補正しながら、認識させる必要があるのではないか?MaskingEYEと勝手に名付けましたが、これはアウフヘーベンの考え、音質評価の未来の想像でもあります。
現在は、画像認識AIでの音質評価と他にも心理音響パラメーターとの融合化をはかり、精度の良い音質評価モデルも考えています。