2020年の後半から、人工知能の研究を始め、2023年に画像認識AIを音質評価に用いるシン・オンシツヒョウカを自動車技術会・Inter–noiseで発表したわけですが、根本的なところ、機械学習がどうして、音質評価に役に立つと2020−2021年に思ったか?それをまとめたいと思います。
最初はプログラミング言語Pythonを学ぼうと始めたわけですが、学んでいるとPythonが主に使われている機械学習に出会ったわけです。機械学習の根幹の考え、この論理に私は衝撃を受けたわけです。従来のアルゴリズム、モデル化を打ち破る手法の機械学習。
まずは、従来のモデル化の考え方の限界をお話ししましょう。
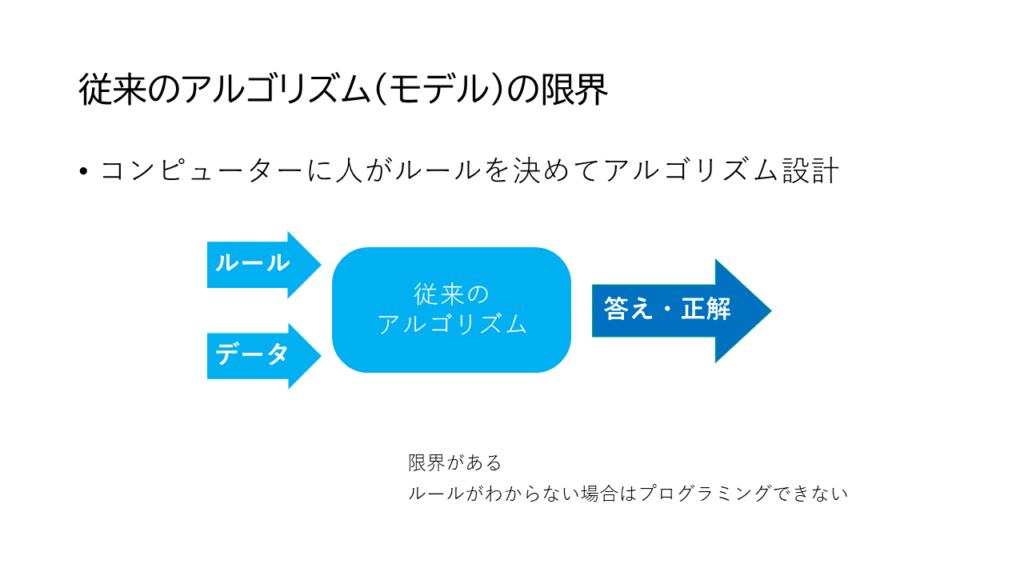
図にもありますように、コンピューターのプログラムというのは、ルールを人が決めないといけないわけです。何でも良いのですが、ルールが分かれば、その条件に合うデータを入力すると正解がわかる、これが従来型のアルゴリズムになります。その限界とAIを用いた機械学習の違いを用いた例をお話ししましょう。

ウォーキング検出アルゴリズムというのを考えてみましょうか。
歩いていました。速度計で測りました、時速4マイルまでが妥当なウォーキングとわかりました。時速4マイルまでをウォーキングとルール設定しました。

次に、アルゴリズムの拡張を行います、時速4マイルより速い場合はランニングとルール追加します。

自転車に乗っている状態も追加しましょう。計測すると時速12マイルまでは、ランニング、それより速いと自転車とルール設定します。
さあ、ここで問題が起きます。

ゴルフ。ゴルフは歩いたり走ったり、止まったり、これをウォーキングと判断されても困るし、ゴルフという運動をしていることをどうやって検出すればいいのか????ここにルールベースの限界があるわけです。
ここで、コペルニクス級転回をします。
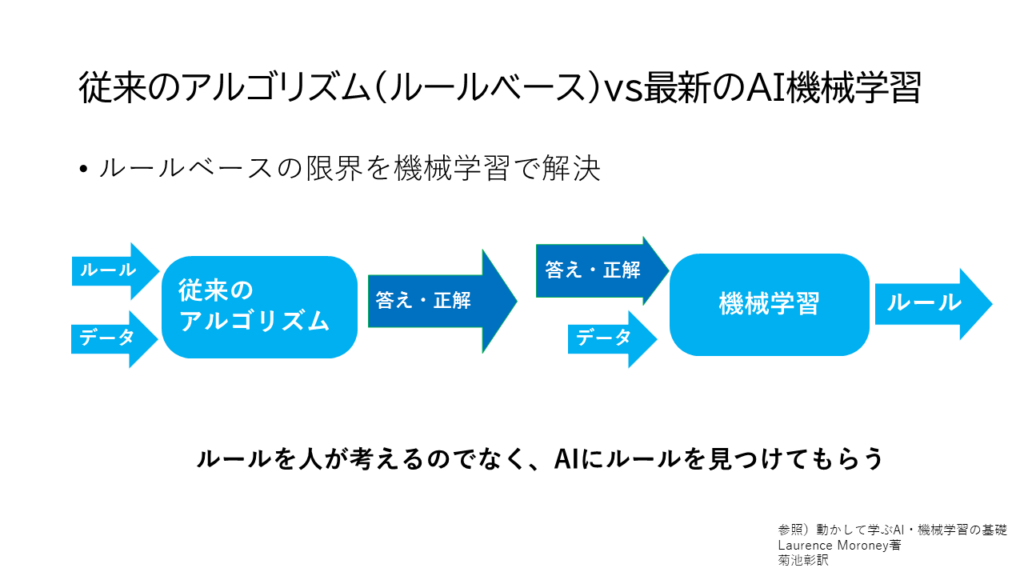
ルール、データ、正解の並びを入れ替えて考えることをします。つまり、先に正解を与えて、それに関するデータを与えます。それを学習させていきAIにルールを見つけてもらう。ルールがわからないので、AIにルールを見つけてもらおう、これが機械学習になります。
ゴルフの例に考えましょうか。

エクセサイズに関係しそうな、心拍数、位置情報、速度などのデータを収集します。そのデータにラベルを貼ります。ウォーキング、ランニング、自転車、ゴルフということをすると、AI側が勝手に機械学習をして分類するアルゴリズムを、モデル化をしてくれます。
待て待て、こんな方法がありなのか?
音質評価で用いている、心理音響パラメーターは全部モデル化だったはず。心理音響パラメーターを完全に否定している機械学習やん!?
つまり心理音響パラメーターを一旦全部捨てて、AIに機械学習させて、音質評価モデルを作ればいいじゃん→心理音響断捨離を考えついたわけです。(この時点で私は20年近く心理音響パラメーターを研究してました、、、、)
で、どのAIを用いるか、画像認識AIに着目しました。AIの能力が際立っていたのが一因です。
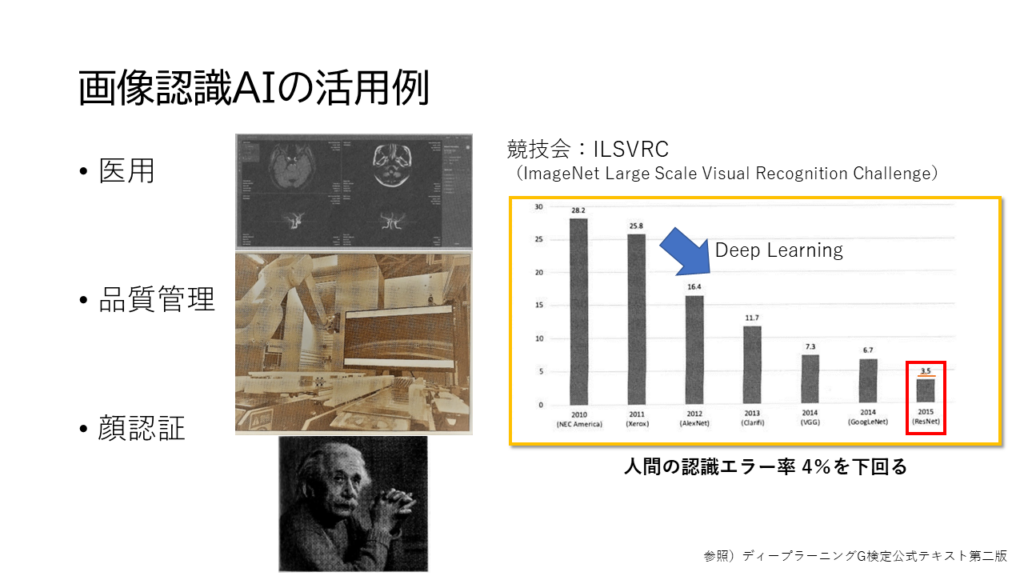
様々な分野使われていましたし、競技会でも人間の認識を上回っているのでいけるのではないか?と。どのくらい使えるのか?私も確認しました。寿司画像判定AIです。
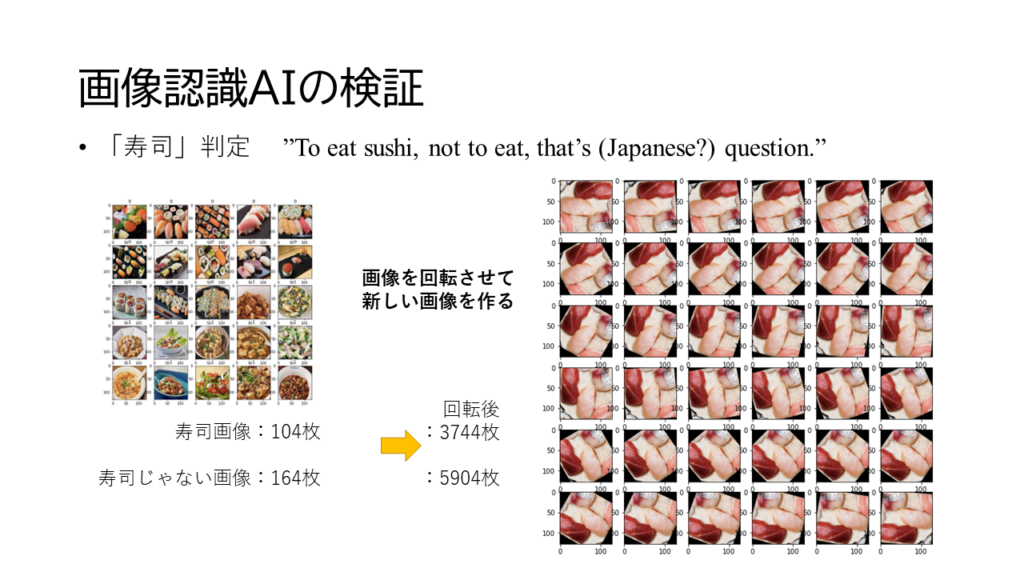
重要なのは画像がたくさんあることで、AIの画像認識は人間と異なり、昆虫的というか、回転させても同じ画像と認識しない特徴を逆に利用して、同じ画像を回転させて一括ラベリングで画像を増やす方法が存在していると。増やすとやっぱり精度が上がるわけです。
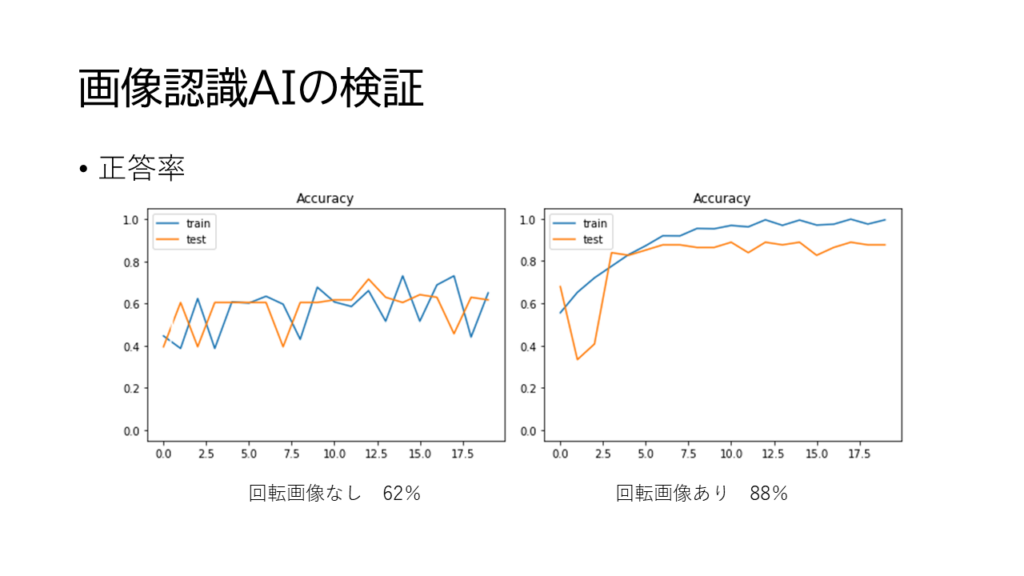
個別検証すると、寿司の判定ができるわけですが、カルフォルニアロールはあんまり寿司っぽくないとAIに言われました。こういうところで人間を上回っているのね。

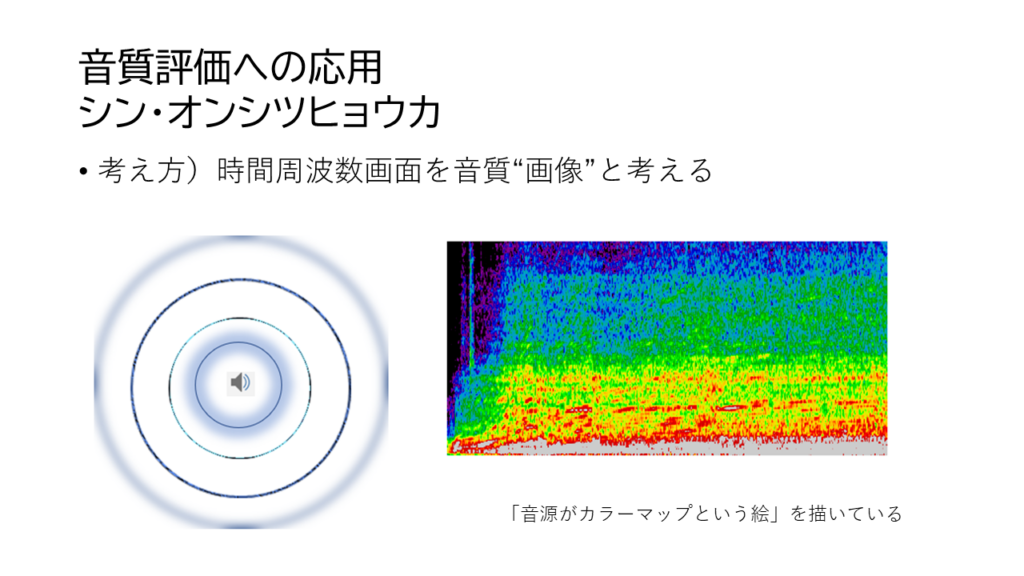
アニメ・エヴァンゲリンオンの庵野監督の影響と言いますか、AIを使うものはどうやら世の中的にシン・何とからしいので、「シン・オンシツヒョウカ」と勝手に命名しました。使うのは画像認識AI、そしてその画像はまずは、時間周波数画面を音質画像と捉えて評価しました。

最初に行ったのは、こんな三つの評価ですね。純音かフィルター音か。
異音があるかないか。フェラーリの音かどうか。
自動車技術会でもinter-noiseでも好評でした。ありがとうございました。シン・オンシツヒョウカを他の音にも使うことを続けています。